
As follow up to the Exadata as Code post, today I’m going to focus on one of the latest features added to our automation: PDB Snapshot Cloning.
PDB snapshot cloning is one of the best development options to offers in a CI/CD project. In an Exadata environment there are special requirements to implement before start using this technology: Sparse Grid Disks and Sparse ASM Disk Group ( description and step-by-step example is available here).
On Exadata, the PDB Snapshot beneficial of all Smart features including offload capabilities, with in addition space- and time-efficient provisioning.
After this brief introduction let’s see how the PDB Snapshot Cloning has been implemented on our Exadata as Code automation.
Exadata Sparse Storage Automation
Select the Oracle Container Database (CDB) where the PDB Snapshot Cloning should be activated, and with One-click provisioning the Sparse Grid disks and Sparse ASM disk group are created.
After the initial provisioning, the automation starts monitoring the space usage, automatically resizing it (increasing/decreasing) when necessary.
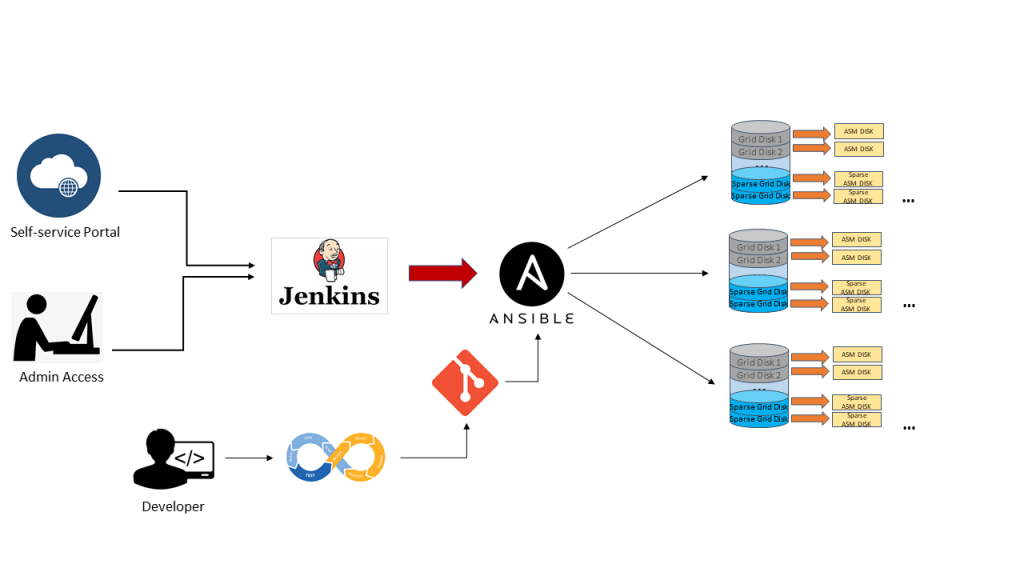
Automated storage lifecycle management
PDB Snapshot Cloning Automation
Same principle applies to the different PDB actions: One-click Provisioning/Decommissioning of the PDB Test Master and PDB Snapshot.
Those features are exposed via UI or API to the application developers, making them autonomous on the management of such space efficient database environment.


Hello, I loved your article and if possible I would like to take some questions.
I’m an Oracle DBA, and I’m trying to insert the devops culture into my day to day, but the tools for onpremise environments are quite scarce.
Is the UI or API that is exposed to developers, provided by jenkins? I didn’t quite understand the flow drawn.
Thank you for your attention and great post
LikeLike
Hi Henrique,
First of all thank you for the feedback.
With Jenkins both options are possible (UI and API), you can find the details here: https://www.jenkins.io/doc/book/using/remote-access-api/
LikeLike