After more than 11 year from the launch Oracle Exadata Machine has become popular on many companies across industries, making administrators, developers and final users almost unanimously satisfied about performance and availability.
But also, on Exadata there are cumbersome maintenance activities like patching.
Most of my Exadata customers have acquired 2 non-full RACKs, which makes the patching effort quite reasonable; but recently I started working on a project with multiple full RACKs, with tens of Storage Servers, Compute Nodes and hundreds of Virtual Machines…
A very challenging environment, especially when it came to patching…
Patching all the systems using the standard patchmgr utiliy was not acceptable, therefore I had to replace my standard patching procedure with a new one offering automation and scalability.
At this subject Oracle provides few handy options:
Patching Exadata Infrastructure
- Storage Server Patching via http/https server: starting with Oracle Exadata System Software release 18.1.0.0.0, it is possible to patch the Storage Servers using an external http server hosting the new software image. The activitiy can be scheduled up to one week before the installation, allowing on each Cell the Management Server (MS) to start downloading and run pre-checks in advance. MS interrupts the software upgrade and generates an alert if the Cell does not comply with all pre-requisites.
- Unbreakable Linux Network: ULN offers software patches, updates, and fixes for Oracle Linux and Oracle VM. The implementation of a local YUM repository leverages the patch automation of the bare metal OS or dom0/domU.
- InfiniBand Switch: standard rolling upgrade patching procedure using patchmgr.
Patching Grid Infrastructure & RDBMS
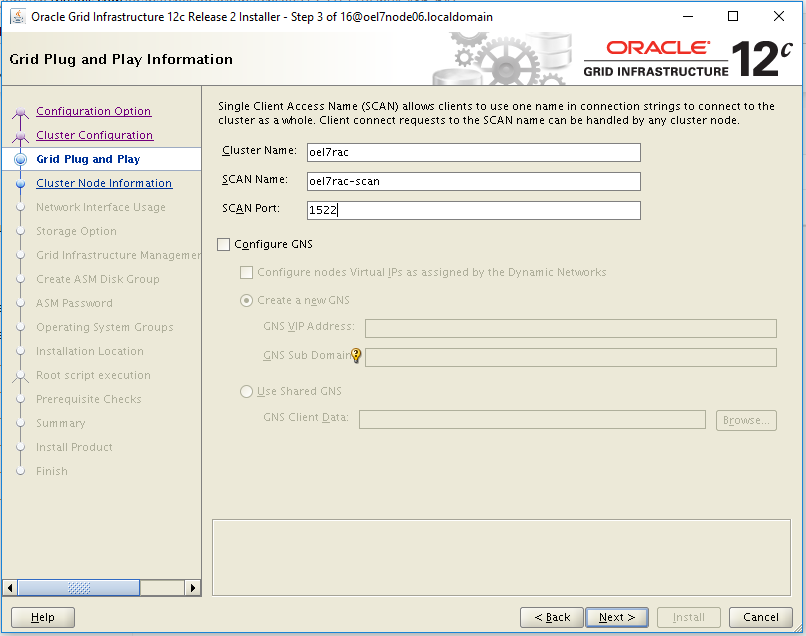
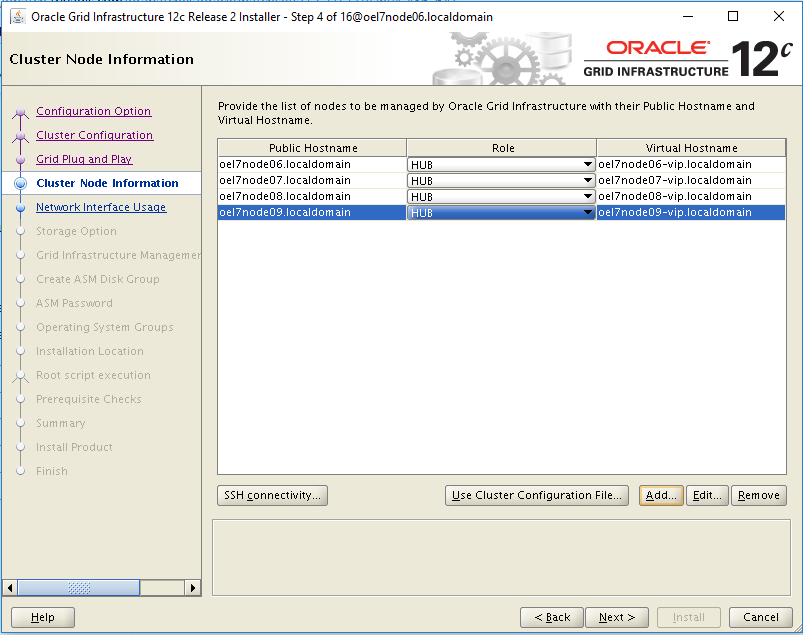
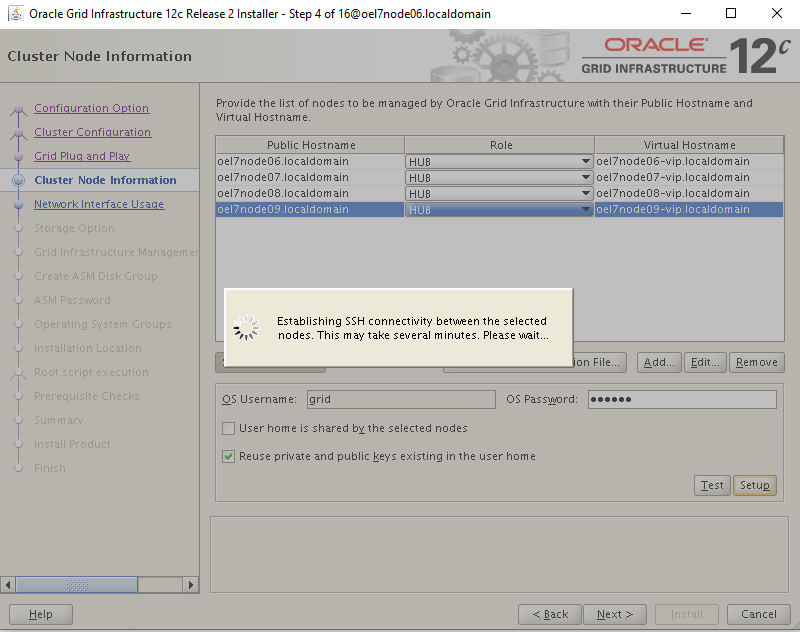
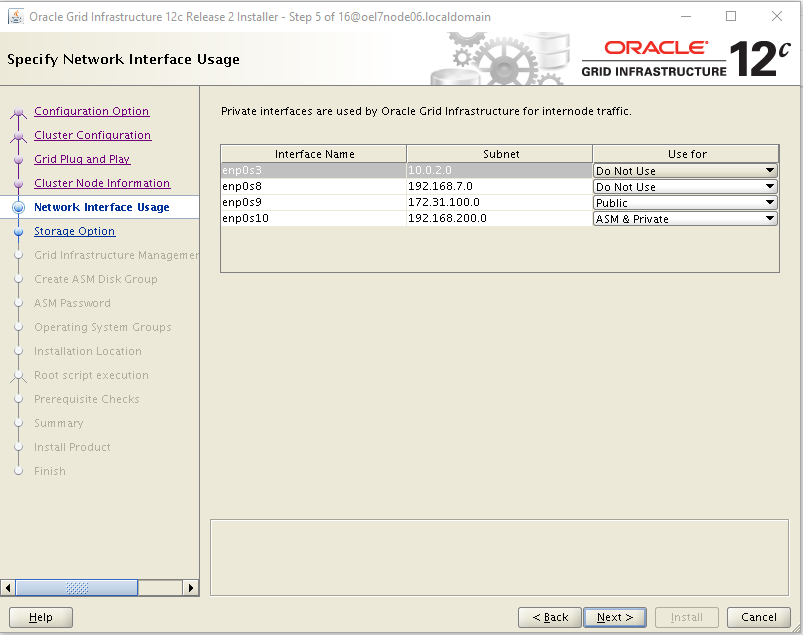
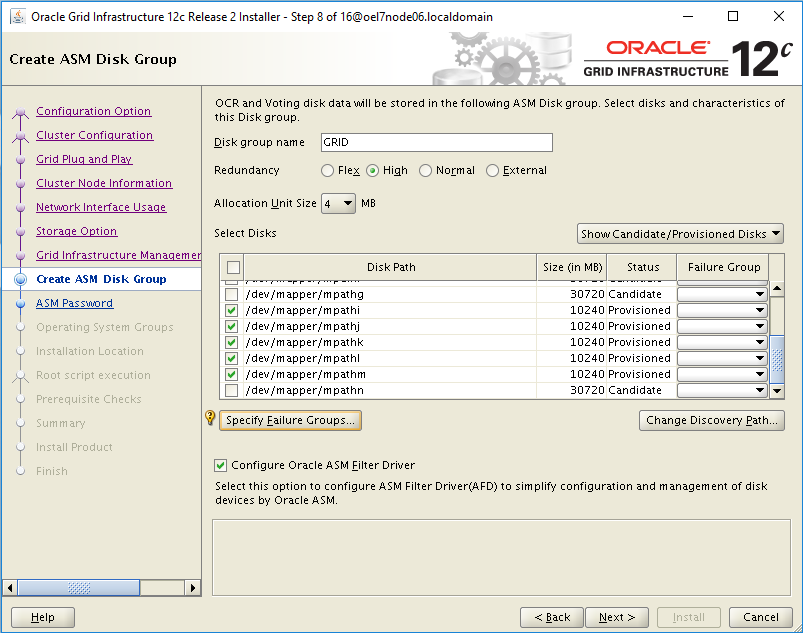
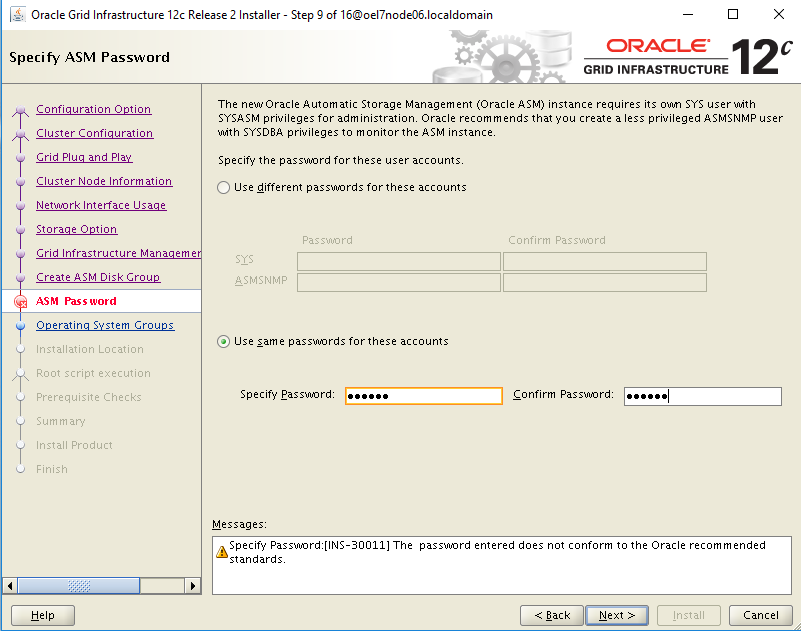
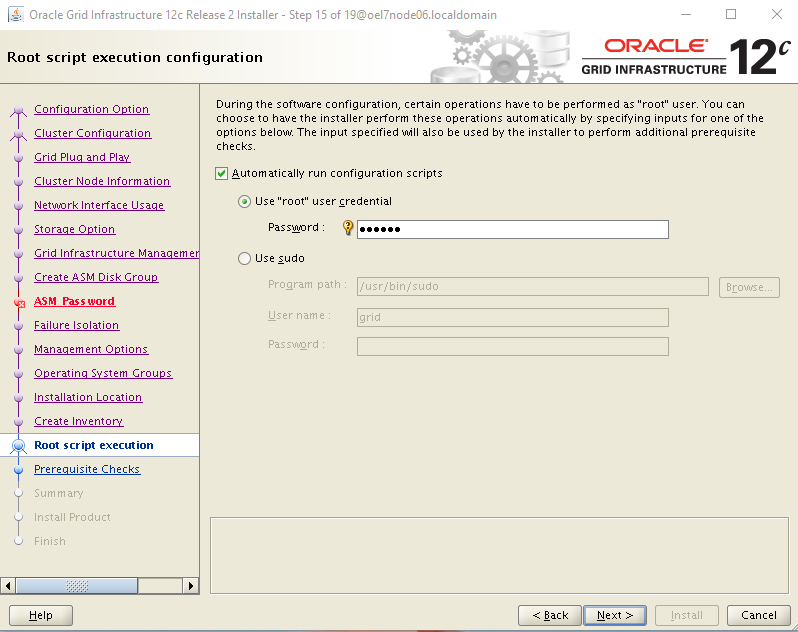
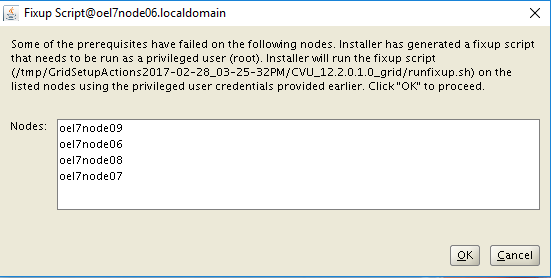
- GI & RDBMS: those components are patched using the standard Oracle tools common to all platforms, but the entire process has been parallalized using OS tools like dcli commands.
Overview Bulk Exadata Patching

Main Patching Commands
Storage Server – Scheduling Automated Storage Server Update via HTTP/HTTPS
On the Storage Cell set the local Apache location hosting the cell software
[root@efucndb01-a ~]# dcli -l root -g ~/cells cellcli -e 'alter softwareUpdate store=\"http://uln-yum.emilianofusaglia.net/cellsw\"' efucncel01-a: Software Update successfully altered. efucncel02-a: Software Update successfully altered. efucncel03-a: Software Update successfully altered. efucncel04-a: Software Update successfully altered. efucncel05-a: Software Update successfully altered. efucncel06-a: Software Update successfully altered. efucncel07-a: Software Update successfully altered. efucncel08-a: Software Update successfully altered. efucncel09-a: Software Update successfully altered. efucncel10-a: Software Update successfully altered. efucncel11-a: Software Update successfully altered. efucncel12-a: Software Update successfully altered. efucncel13-a: Software Update successfully altered. efucncel14-a: Software Update successfully altered. [root@efucndb01-a ~]#
Schedule the update
[root@efucndb01-a ~]# dcli -l root -g ~/cells cellcli -e 'alter softwareUpdate time=\"03:20 AM WEDNESDAY\"' efucncel01-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel02-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel03-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel04-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel05-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel06-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel07-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel08-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel09-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel10-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel11-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel12-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel13-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. efucncel14-a: Software update is scheduled to begin at: 2020-02-05T03:20:00+01:00. [root@efucndb01-a ~]#
Verify the scheduled upgrade
[root@efucndb01-a ~]# dcli -l root -g ~/cells cellcli -e 'list softwareupdate detail' efucncel01-a: name: 19.3.4.0.0.200130 efucncel01-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel01-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel01-a: time: 2020-02-05T03:20:00+01:00 efucncel02-a: name: 19.3.4.0.0.200130 efucncel02-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel02-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel02-a: time: 2020-02-05T03:20:00+01:00 efucncel03-a: name: 19.3.4.0.0.200130 efucncel03-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel03-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel03-a: time: 2020-02-05T03:20:00+01:00 efucncel04-a: name: 19.3.4.0.0.200130 efucncel04-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel04-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel04-a: time: 2020-02-05T03:20:00+01:00 efucncel05-a: name: 19.3.4.0.0.200130 efucncel05-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel05-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel05-a: time: 2020-02-05T03:20:00+01:00 efucncel06-a: name: 19.3.4.0.0.200130 efucncel06-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel06-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel06-a: time: 2020-02-05T03:20:00+01:00 efucncel07-a: name: 19.3.4.0.0.200130 efucncel07-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel07-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel07-a: time: 2020-02-05T03:20:00+01:00 efucncel08-a: name: 19.3.4.0.0.200130 efucncel08-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel08-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel08-a: time: 2020-02-05T03:20:00+01:00 efucncel09-a: name: 19.3.4.0.0.200130 efucncel09-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel09-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel09-a: time: 2020-02-05T03:20:00+01:00 efucncel10-a: name: 19.3.4.0.0.200130 efucncel10-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel10-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel10-a: time: 2020-02-05T03:20:00+01:00 efucncel11-a: name: 19.3.4.0.0.200130 efucncel11-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel11-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel11-a: time: 2020-02-05T03:20:00+01:00 efucncel12-a: name: 19.3.4.0.0.200130 efucncel12-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel12-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel12-a: time: 2020-02-05T03:20:00+01:00 efucncel13-a: name: 19.3.4.0.0.200130 efucncel13-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel13-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel13-a: time: 2020-02-05T03:20:00+01:00 efucncel14-a: name: 19.3.4.0.0.200130 efucncel14-a: status: PreReq OK. Ready to update at: 2020-02-05T03:20:00+01:00 efucncel14-a: store: http://uln-yum.emilianofusaglia.net/cellsw efucncel14-a: time: 2020-02-05T03:20:00+01:00 [root@efucndb01-a ~]#
Unbreakable Linux Network
dom0 checks
[root@efuconsole dbserver_patch_19.200120]# ./patchmgr -dbnodes ~/dom0 -precheck -yum_repo http://uln-yum.emilianofusaglia.net/yum/EngineeredSystems/exadata/dbserver/dom0/19.3.4.0.0/base/x86_64 -target_version 19.3.4.0.0.200130 NOTE patchmgr release: 19.200120 (always check MOS 1553103.1 for the latest release of dbserver.patch.zip) NOTE WARNING Do not interrupt the patchmgr session. WARNING Do not resize the screen. It may disturb the screen layout. WARNING Do not reboot database nodes during update or rollback. WARNING Do not open logfiles in write mode and do not try to alter them. 2020-02-06 14:06:17 +0100 :Working: Verify SSH equivalence for the root user to node(s) 2020-02-06 14:06:19 +0100 :SUCCESS: Verify SSH equivalence for the root user to node(s) 2020-02-06 14:06:22 +0100 :Working: Initiate precheck on 8 node(s) 2020-02-06 14:07:36 +0100 :Working: Check free space on node(s) 2020-02-06 14:07:42 +0100 :SUCCESS: Check free space on node(s) 2020-02-06 14:08:07 +0100 :Working: dbnodeupdate.sh running a precheck on node(s). 2020-02-06 14:09:43 +0100 :SUCCESS: Initiate precheck on node(s). 2020-02-06 14:09:45 +0100 :SUCCESS: Completed run of command: ./patchmgr -dbnodes /root/dom0 -precheck -yum_repo http://uln-yum.emilianofusaglia.net/yum/EngineeredSystems/exadata/dbserver/dom0/19.3.4.0.0/base/x86_64 -target_version 19.3.4.0.0.200130 2020-02-06 14:09:45 +0100 :INFO : Precheck attempted on nodes in file /root/dom0: [efucndb01-a efucndb02-a efucndb03-a efucndb04-a efucndb05-a efucndb06-a efucndb07-a efucndb08-a] 2020-02-06 14:09:45 +0100 :INFO : Current image version on dbnode(s) is: 2020-02-06 14:09:45 +0100 :INFO : efucndb01-a: 19.2.6.0.0.190911.1 2020-02-06 14:09:45 +0100 :INFO : efucndb02-a: 19.2.6.0.0.190911.1 2020-02-06 14:09:45 +0100 :INFO : efucndb03-a: 19.2.6.0.0.190911.1 2020-02-06 14:09:45 +0100 :INFO : efucndb04-a: 19.2.6.0.0.190911.1 2020-02-06 14:09:45 +0100 :INFO : efucndb05-a: 19.2.6.0.0.190911.1 2020-02-06 14:09:45 +0100 :INFO : efucndb06-a: 19.2.6.0.0.190911.1 2020-02-06 14:09:45 +0100 :INFO : efucndb07-a: 19.2.6.0.0.190911.1 2020-02-06 14:09:45 +0100 :INFO : efucndb08-a: 19.2.6.0.0.190911.1 2020-02-06 14:09:45 +0100 :INFO : For details, check the following files in /EXAVMIMAGES/Patch/patchmgr_DBSERVER/dbserver_patch_19.200120: 2020-02-06 14:09:45 +0100 :INFO : - _dbnodeupdate.log 2020-02-06 14:09:45 +0100 :INFO : - patchmgr.log 2020-02-06 14:09:45 +0100 :INFO : - patchmgr.trc 2020-02-06 14:09:45 +0100 :INFO : Exit status:0 2020-02-06 14:09:45 +0100 :INFO : Exiting. [root@efucndb01-a dbserver_patch_19.200120]#
dom0 upgrade
[root@efuconsole dbserver_patch_19.200120]# ./patchmgr -dbnodes ~/dom0 -upgrade -yum_repo http://uln-yum.emilianofusaglia.net/yum/EngineeredSystems/exadata/dbserver/dom0/19.3.4.0.0/base/x86_64 -target_version 19.3.4.0.0.200130 NOTE patchmgr release: 19.200120 (always check MOS 1553103.1 for the latest release of dbserver.patch.zip) NOTE NOTE Database nodes will reboot during the update process. NOTE WARNING Do not interrupt the patchmgr session. WARNING Do not resize the screen. It may disturb the screen layout. WARNING Do not reboot database nodes during update or rollback. WARNING Do not open logfiles in write mode and do not try to alter them. 2020-02-06 14:29:11 +0100 :Working: Verify SSH equivalence for the root user to node(s) 2020-02-06 14:29:13 +0100 :SUCCESS: Verify SSH equivalence for the root user to node(s) 2020-02-06 14:29:15 +0100 :Working: Initiate prepare steps on node(s). 2020-02-06 14:29:17 +0100 :Working: Check free space on node(s) 2020-02-06 14:29:23 +0100 :SUCCESS: Check free space on node(s) 2020-02-06 14:29:59 +0100 :SUCCESS: Initiate prepare steps on node(s). 2020-02-06 14:29:59 +0100 :Working: Initiate update on 8 node(s). 2020-02-06 14:29:59 +0100 :Working: dbnodeupdate.sh running a backup on 8 node(s). 2020-02-06 14:36:16 +0100 :SUCCESS: dbnodeupdate.sh running a backup on 8 node(s). 2020-02-06 14:36:16 +0100 :Working: Initiate update on node(s) 2020-02-06 14:36:16 +0100 :Working: Get information about any required OS upgrades from node(s). 2020-02-06 14:36:28 +0100 :SUCCESS: Get information about any required OS upgrades from node(s). 2020-02-06 14:36:28 +0100 :Working: dbnodeupdate.sh running an update step on all nodes. 2020-02-06 14:56:38 +0100 :INFO : efucndb01-a is ready to reboot. 2020-02-06 14:56:38 +0100 :INFO : efucndb02-a is ready to reboot. 2020-02-06 14:56:38 +0100 :INFO : efucndb03-a is ready to reboot. 2020-02-06 14:56:38 +0100 :INFO : efucndb04-a is ready to reboot. 2020-02-06 14:56:38 +0100 :INFO : efucndb05-a is ready to reboot. 2020-02-06 14:56:38 +0100 :INFO : efucndb06-a is ready to reboot. 2020-02-06 14:56:38 +0100 :INFO : efucndb07-a is ready to reboot. 2020-02-06 14:56:38 +0100 :INFO : efucndb08-a is ready to reboot. 2020-02-06 14:56:39 +0100 :SUCCESS: dbnodeupdate.sh running an update step on all nodes. 2020-02-06 14:56:51 +0100 :Working: Initiate reboot on node(s) 2020-02-06 14:56:55 +0100 :SUCCESS: Initiate reboot on node(s) 2020-02-06 14:56:55 +0100 :Working: Waiting to ensure node(s) is down before reboot. 2020-02-06 14:58:20 +0100 :SUCCESS: Waiting to ensure node(s) is down before reboot. 2020-02-06 14:58:20 +0100 :Working: Waiting to ensure node(s) is up after reboot. 2020-02-06 15:04:23 +0100 :SUCCESS: Waiting to ensure node(s) is up after reboot. 2020-02-06 15:04:23 +0100 :Working: Waiting to connect to node(s) with SSH. During Linux upgrades this can take some time. 2020-02-06 15:27:46 +0100 :SUCCESS: Waiting to connect to node(s) with SSH. During Linux upgrades this can take some time. 2020-02-06 15:27:46 +0100 :Working: Wait for node(s) is ready for the completion step of update. 2020-02-06 15:31:29 +0100 :SUCCESS: Wait for node(s) is ready for the completion step of update. 2020-02-06 15:31:30 +0100 :Working: Initiate completion step from dbnodeupdate.sh on node(s) 2020-02-06 15:48:10 +0100 :SUCCESS: Initiate completion step from dbnodeupdate.sh on efucndb01-a 2020-02-06 15:48:14 +0100 :SUCCESS: Initiate completion step from dbnodeupdate.sh on efucndb02-a 2020-02-06 15:48:19 +0100 :SUCCESS: Initiate completion step from dbnodeupdate.sh on efucndb03-a 2020-02-06 15:48:30 +0100 :SUCCESS: Initiate completion step from dbnodeupdate.sh on efucndb04-a 2020-02-06 15:48:35 +0100 :SUCCESS: Initiate completion step from dbnodeupdate.sh on efucndb05-a 2020-02-06 15:48:46 +0100 :SUCCESS: Initiate completion step from dbnodeupdate.sh on efucndb06-a 2020-02-06 15:48:50 +0100 :SUCCESS: Initiate completion step from dbnodeupdate.sh on efucndb07-a 2020-02-06 15:49:02 +0100 :SUCCESS: Initiate completion step from dbnodeupdate.sh on efucndb08-a 2020-02-06 15:49:18 +0100 :SUCCESS: Initiate update on node(s). 2020-02-06 15:49:18 +0100 :SUCCESS: Initiate update on 0 node(s). [INFO ] Collected dbnodeupdate diag in file: Diag_patchmgr_dbnode_upgrade_060220142909.tbz -rw-r--r-- 1 root root 6381043 Feb 6 15:49 Diag_patchmgr_dbnode_upgrade_060220142909.tbz 2020-02-06 15:49:22 +0100 :SUCCESS: Completed run of command: ./patchmgr -dbnodes /root/dom0 -upgrade -yum_repo http://uln-yum.emilianofusaglia.net/yum/EngineeredSystems/exadata/dbserver/dom0/19.3.4.0.0/base/x86_64 -target_version 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : Upgrade attempted on nodes in file /root/dom0: [efucndb01-a efucndb02-a efucndb03-a efucndb04-a efucndb05-a efucndb06-a efucndb07-a efucndb08-a] 2020-02-06 15:49:22 +0100 :INFO : Current image version on dbnode(s) is: 2020-02-06 15:49:22 +0100 :INFO : efucndb01-a: 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : efucndb02-a: 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : efucndb03-a: 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : efucndb04-a: 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : efucndb05-a: 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : efucndb06-a: 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : efucndb07-a: 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : efucndb08-a: 19.3.4.0.0.200130 2020-02-06 15:49:22 +0100 :INFO : For details, check the following files in /EXAVMIMAGES/Patch/patchmgr_DBSERVER/dbserver_patch_19.200120: 2020-02-06 15:49:22 +0100 :INFO : - _dbnodeupdate.log 2020-02-06 15:49:22 +0100 :INFO : - patchmgr.log 2020-02-06 15:49:22 +0100 :INFO : - patchmgr.trc 2020-02-06 15:49:22 +0100 :INFO : Exit status:0 2020-02-06 15:49:22 +0100 :INFO : Exiting.
InfiniBand Switch
IB switch checks
[root@efucndb01-a patch_switch_19.3.4.0.0.200130]# ./patchmgr -ibswitches ~/ibs -upgrade -ibswitch_precheck 2020-02-10 07:57:44 +0100 :Working: Verify SSH equivalence for the root user to node(s) 2020-02-10 07:57:46 +0100 :SUCCESS: Verify SSH equivalence for the root user to node(s) 2020-02-10 07:57:47 +0100 1 of 1 :Working: Initiate pre-upgrade validation check on InfiniBand switch(es). ----- InfiniBand switch update process started 2020-02-10 07:57:48 +0100 ----- [NOTE ] Log file at /EXAVMIMAGES/Patch/IBs_19.3.4.0.0/patch_switch_19.3.4.0.0.200130/upgradeIBSwitch.log [INFO ] List of InfiniBand switches for upgrade: ( efucnsw-iba01-a efucnsw-ibb01-a ) [SUCCESS ] Verifying Network connectivity to efucnsw-iba01-a [SUCCESS ] Verifying Network connectivity to efucnsw-ibb01-a [SUCCESS ] Validating verify-topology output [INFO ] Master Subnet Manager is set to "efucnsw-iba01-a" in all Switches [INFO ] ---------- Starting with InfiniBand Switch efucnsw-iba01-a [WARNING ] Infiniband switch meets minimal version requirements, but downgrade is only available to 2.2.13-2 with the current package. To downgrade to other versions: Manually download the InfiniBand switch firmware package to the patch directory Set export variable "EXADATA_IMAGE_IBSWITCH_DOWNGRADE_VERSION" to the appropriate version Run patchmgr command to initiate downgrade. [SUCCESS ] Verify SSH access to the patchmgr host efucndb01-a.emilianofusaglia.net from the InfiniBand Switch efucnsw-iba01-a. [INFO ] Starting pre-update validation on efucnsw-iba01-a [SUCCESS ] Verifying that /tmp has 150M in efucnsw-iba01-a, found 492M [SUCCESS ] Verifying that / has 20M in efucnsw-iba01-a, found 28M [SUCCESS ] NTP daemon is running on efucnsw-iba01-a. [INFO ] Manually validate the following entries Date:(YYYY-aM-DD) 2020-02-10 Time:(HH:MM:SS) 07:58:05 [INFO ] Validating the current firmware on the InfiniBand Switch [SUCCESS ] Firmware verification on InfiniBand switch efucnsw-iba01-a [SUCCESS ] Verifying that the patchmgr host efucndb01-a.emilianofusaglia.net is recognized on the InfiniBand Switch efucnsw-iba01-a through getHostByName [SUCCESS ] Execute plugin check for Patch Check Prereq on efucnsw-iba01-a [INFO ] Finished pre-update validation on efucnsw-iba01-a [SUCCESS ] Pre-update validation on efucnsw-iba01-a [SUCCESS ] Prereq check on efucnsw-iba01-a [INFO ] ---------- Starting with InfiniBand Switch efucnsw-ibb01-a [WARNING ] Infiniband switch meets minimal version requirements, but downgrade is only available to 2.2.13-2 with the current package. To downgrade to other versions: Manually download the InfiniBand switch firmware package to the patch directory Set export variable "EXADATA_IMAGE_IBSWITCH_DOWNGRADE_VERSION" to the appropriate version Run patchmgr command to initiate downgrade. [SUCCESS ] Verify SSH access to the patchmgr host efucndb01-a.emilianofusaglia.net from the InfiniBand Switch efucnsw-ibb01-a. [INFO ] Starting pre-update validation on efucnsw-ibb01-a [SUCCESS ] Verifying that /tmp has 150M in efucnsw-ibb01-a, found 492M [SUCCESS ] Verifying that / has 20M in efucnsw-ibb01-a, found 28M [SUCCESS ] NTP daemon is running on efucnsw-ibb01-a. [INFO ] Manually validate the following entries Date:(YYYY-aM-DD) 2020-02-10 Time:(HH:MM:SS) 07:58:25 [INFO ] Validating the current firmware on the InfiniBand Switch [SUCCESS ] Firmware verification on InfiniBand switch efucnsw-ibb01-a [SUCCESS ] Verifying that the patchmgr host efucndb01-a.emilianofusaglia.net is recognized on the InfiniBand Switch efucnsw-ibb01-a through getHostByName [SUCCESS ] Execute plugin check for Patch Check Prereq on efucnsw-ibb01-a [INFO ] Finished pre-update validation on efucnsw-ibb01-a [SUCCESS ] Pre-update validation on efucnsw-ibb01-a [SUCCESS ] Prereq check on efucnsw-ibb01-a [SUCCESS ] Overall status ----- InfiniBand switch update process ended 2020-02-10 07:58:42 +0100 ----- 2020-02-10 07:58:42 +0100 1 of 1 :SUCCESS: Initiate pre-upgrade validation check on InfiniBand switch(es). 2020-02-10 07:58:42 +0100 :SUCCESS: Completed run of command: ./patchmgr -ibswitches /root/ibs -upgrade -ibswitch_precheck 2020-02-10 07:58:42 +0100 :INFO : upgrade attempted on nodes in file /root/ibs: [efucnsw-iba01-a efucnsw-ibb01-a] 2020-02-10 07:58:42 +0100 :INFO : For details, check the following files in /EXAVMIMAGES/Patch/IBs_19.3.4.0.0/patch_switch_19.3.4.0.0.200130: 2020-02-10 07:58:42 +0100 :INFO : - upgradeIBSwitch.log 2020-02-10 07:58:42 +0100 :INFO : - upgradeIBSwitch.trc 2020-02-10 07:58:42 +0100 :INFO : - patchmgr.stdout 2020-02-10 07:58:42 +0100 :INFO : - patchmgr.stderr 2020-02-10 07:58:42 +0100 :INFO : - patchmgr.log 2020-02-10 07:58:42 +0100 :INFO : - patchmgr.trc 2020-02-10 07:58:42 +0100 :INFO : Exit status:0 2020-02-10 07:58:42 +0100 :INFO : Exiting. [root@efucndb01-a patch_switch_19.3.4.0.0.200130]#
IB switch upgrade
[root@efucndb01-a patch_switch_19.3.4.0.0.200130]# ./patchmgr -ibswitches ~/ibs -upgrade 2020-02-10 07:59:22 +0100 :Working: Verify SSH equivalence for the root user to node(s) 2020-02-10 07:59:24 +0100 :SUCCESS: Verify SSH equivalence for the root user to node(s) 2020-02-10 07:59:25 +0100 1 of 1 :Working: Initiate upgrade of InfiniBand switches to 2.2.14-1. Expect up to 40 minutes for each switch ----- InfiniBand switch update process started 2020-02-10 07:59:25 +0100 ----- [NOTE ] Log file at /EXAVMIMAGES/Patch/IBs_19.3.4.0.0/patch_switch_19.3.4.0.0.200130/upgradeIBSwitch.log [INFO ] List of InfiniBand switches for upgrade: ( efucnsw-iba01-a efucnsw-ibb01-a ) [SUCCESS ] Verifying Network connectivity to efucnsw-iba01-a [SUCCESS ] Verifying Network connectivity to efucnsw-ibb01-a [SUCCESS ] Validating verify-topology output [INFO ] Proceeding with upgrade of InfiniBand switches to version 2.2.14_1 [INFO ] Master Subnet Manager is set to "efucnsw-iba01-a" in all Switches [INFO ] ---------- Starting with InfiniBand Switch efucnsw-iba01-a [WARNING ] Infiniband switch meets minimal version requirements, but downgrade is only available to 2.2.13-2 with the current package. To downgrade to other versions: Manually download the InfiniBand switch firmware package to the patch directory Set export variable "EXADATA_IMAGE_IBSWITCH_DOWNGRADE_VERSION" to the appropriate version Run patchmgr command to initiate downgrade. [SUCCESS ] Verify SSH access to the patchmgr host efucndb01-a.emilianofusaglia.net from the InfiniBand Switch efucnsw-iba01-a. [INFO ] Starting pre-update validation on efucnsw-iba01-a [SUCCESS ] Verifying that /tmp has 150M in efucnsw-iba01-a, found 492M [SUCCESS ] Verifying that / has 20M in efucnsw-iba01-a, found 26M [SUCCESS ] Service opensmd is running on InfiniBand Switch efucnsw-iba01-a [SUCCESS ] NTP daemon is running on efucnsw-iba01-a. [INFO ] Manually validate the following entries Date:(YYYY-aM-DD) 2020-02-10 Time:(HH:MM:SS) 07:59:41 [INFO ] Validating the current firmware on the InfiniBand Switch [SUCCESS ] Firmware verification on InfiniBand switch efucnsw-iba01-a [SUCCESS ] Verifying that the patchmgr host efucndb01-a.emilianofusaglia.net is recognized on the InfiniBand Switch efucnsw-iba01-a through getHostByName [SUCCESS ] Execute plugin check for Patch Check Prereq on efucnsw-iba01-a [INFO ] Finished pre-update validation on efucnsw-iba01-a [SUCCESS ] Pre-update validation on efucnsw-iba01-a [INFO ] Package will be downloaded at firmware update time via scp [SUCCESS ] Execute plugin check for Patching on efucnsw-iba01-a [INFO ] Starting upgrade on efucnsw-iba01-a to 2.2.14_1. Please give upto 15 mins for the process to complete. DO NOT INTERRUPT or HIT CTRL+C during the upgrade [INFO ] Rebooting efucnsw-iba01-a to complete the firmware update. Wait for 15 minutes before continuing. DO NOT MANUALLY REBOOT THE INFINIBAND SWITCH Connection to efucndb01-a closed by remote host. Connection to efucndb01-a closed. 2020-02-10 08:27:49 +0100 :Working: Verify SSH equivalence for the root user to node(s) 2020-02-10 08:27:51 +0100 :SUCCESS: Verify SSH equivalence for the root user to node(s) 2020-02-10 08:27:52 +0100 1 of 1 :Working: Initiate upgrade of InfiniBand switches to 2.2.14-1. Expect up to 40 minutes for each switch ----- InfiniBand switch update process started 2020-02-10 08:27:52 +0100 ----- [NOTE ] Log file at /EXAVMIMAGES/Patch/IBs_19.3.4.0.0/patch_switch_19.3.4.0.0.200130/upgradeIBSwitch.log [INFO ] List of InfiniBand switches for upgrade: ( efucnsw-iba01-a efucnsw-ibb01-a ) [SUCCESS ] Verifying Network connectivity to efucnsw-iba01-a [SUCCESS ] Verifying Network connectivity to efucnsw-ibb01-a [INFO ] InfiniBand switch efucnsw-iba01-a is already at target version. [SUCCESS ] Validating verify-topology output [INFO ] Proceeding with upgrade of InfiniBand switches to version 2.2.14_1 [INFO ] Master Subnet Manager is set to "efucnsw-ibb01-a" in all Switches [INFO ] ---------- Starting with InfiniBand Switch efucnsw-ibb01-a [WARNING ] Infiniband switch meets minimal version requirements, but downgrade is only available to 2.2.13-2 with the current package. To downgrade to other versions: Manually download the InfiniBand switch firmware package to the patch directory Set export variable "EXADATA_IMAGE_IBSWITCH_DOWNGRADE_VERSION" to the appropriate version Run patchmgr command to initiate downgrade. [SUCCESS ] Verify SSH access to the patchmgr host efucndb01-a.emilianofusaglia.net from the InfiniBand Switch efucnsw-ibb01-a. [INFO ] Starting pre-update validation on efucnsw-ibb01-a [SUCCESS ] Verifying that /tmp has 150M in efucnsw-ibb01-a, found 492M [SUCCESS ] Verifying that / has 20M in efucnsw-ibb01-a, found 26M [SUCCESS ] Service opensmd is running on InfiniBand Switch efucnsw-ibb01-a [SUCCESS ] NTP daemon is running on efucnsw-ibb01-a. [INFO ] Manually validate the following entries Date:(YYYY-aM-DD) 2020-02-10 Time:(HH:MM:SS) 08:28:07 [INFO ] Validating the current firmware on the InfiniBand Switch [SUCCESS ] Firmware verification on InfiniBand switch efucnsw-ibb01-a [SUCCESS ] Verifying that the patchmgr host efucndb01-a.emilianofusaglia.net is recognized on the InfiniBand Switch efucnsw-ibb01-a through getHostByName [SUCCESS ] Execute plugin check for Patch Check Prereq on efucnsw-ibb01-a [INFO ] Finished pre-update validation on efucnsw-ibb01-a [SUCCESS ] Pre-update validation on efucnsw-ibb01-a [INFO ] Package will be downloaded at firmware update time via scp [SUCCESS ] Execute plugin check for Patching on efucnsw-ibb01-a [INFO ] Starting upgrade on efucnsw-ibb01-a to 2.2.14_1. Please give upto 15 mins for the process to complete. DO NOT INTERRUPT or HIT CTRL+C during the upgrade [INFO ] Rebooting efucnsw-ibb01-a to complete the firmware update. Wait for 15 minutes before continuing. DO NOT MANUALLY REBOOT THE INFINIBAND SWITCH Connection to efucndb01-a closed by remote host. Connection to efucndb01-a closed.